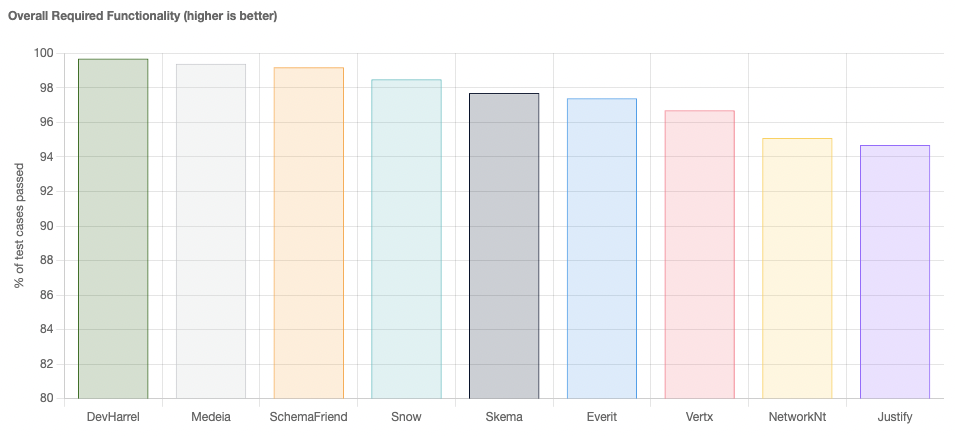
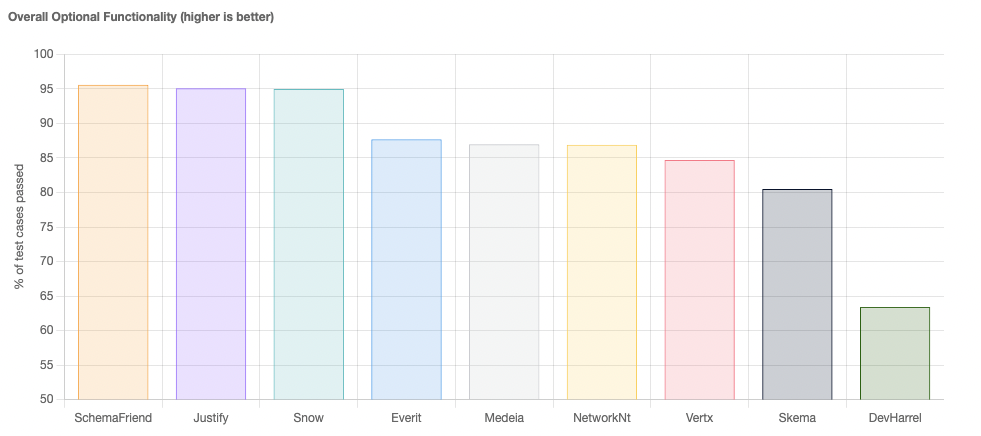
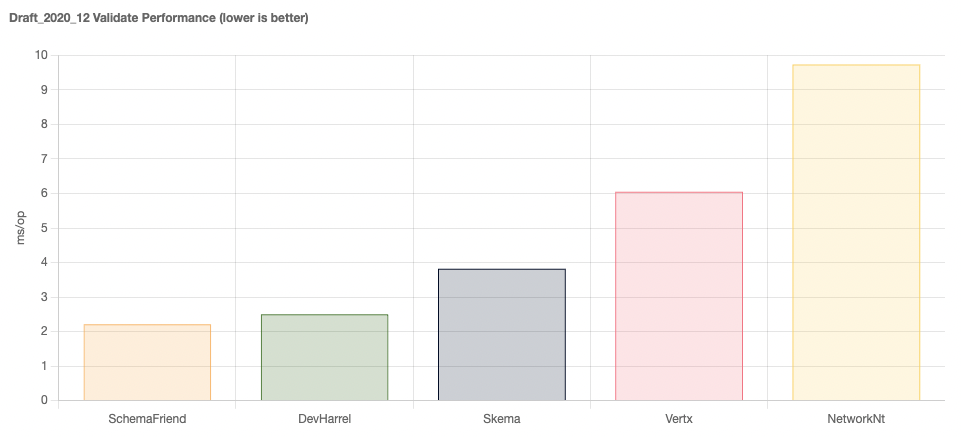
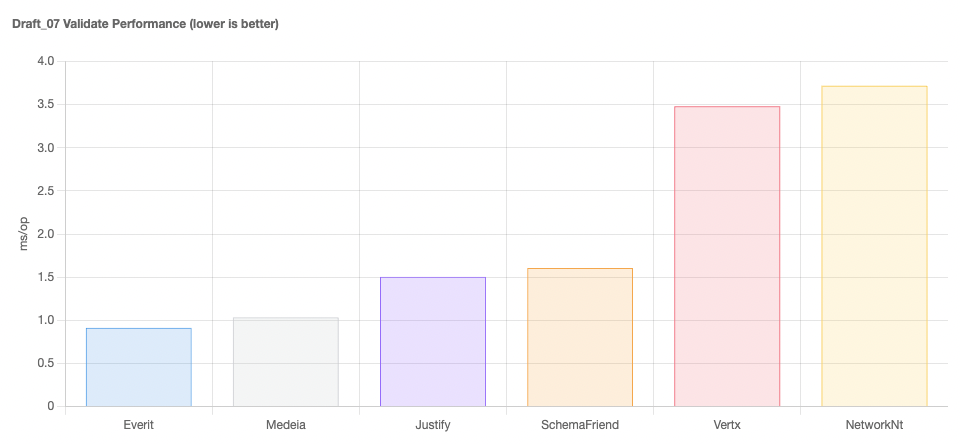
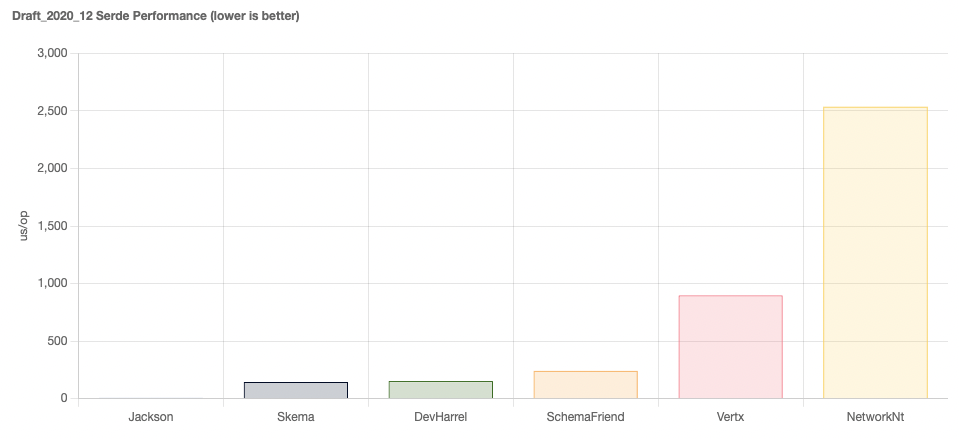
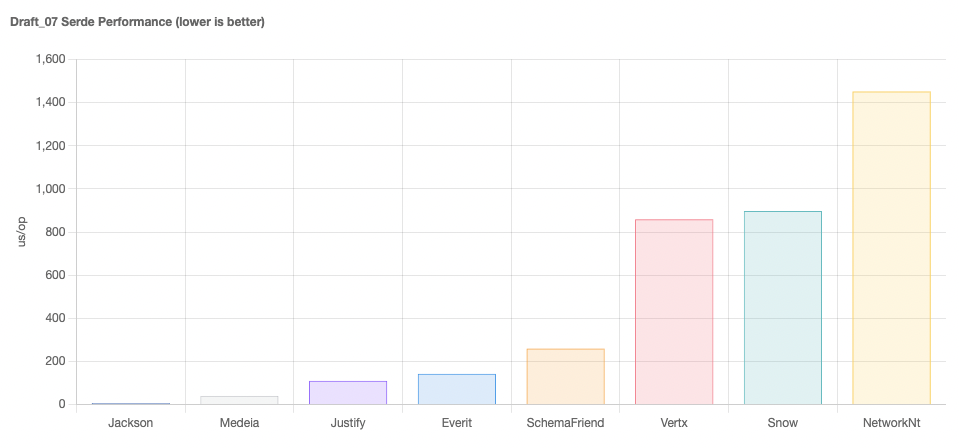
Requirements for JSON schema evolution
How should JSON Schema evolution work? What operations are required to mean we have a useful way to evolve schemas with full compatability?
What we’ve come to expect from other schema types, for example Avro, is that required properties can’t be removed if we want forwards compatibility, or added if we want backwards compatibility. Confluent’s checks already cover this.
It’s the handling of optional properties that needs to change: adding and removing optional properties should be a fully compatible change, but are not supported by Confluent’s checks.
This gives us the following requirements in table form:
| Forward Compatible Old schema / new data |
Backwards Compatible New schema / old data |
Fully Compatible | |
|---|---|---|---|
| Add required | :heavy_check_mark: | :x: | :x: |
| Add optional | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| Remove required | :x: | :heavy_check_mark: | :x: |
| Remove optional | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| Optional -> required | :heavy_check_mark: | :x: | :x: |
| Required -> Optional | :x: | :heavy_check_mark: | :x: |
If JSON Schema compatability checks supported these operations it would be user-friendly and applicable to real-world use-cases.
Splitting readers and writers
So how can we achieve full compatibility when adding and removing optional fields?
Simple. We differentiate between the schemas used to produce the data from those used to consume the data.
Because producing schemas are never used to consume data, there is no requirement for producing schemas to be compatible with each other. Likewise, there is no requirement for consuming schemas to be compatible with each other, as they never produce data. All that matters is compatability between producing and consuming schemas.
The figure below shows how this would work when adding a new consuming schema C2 and a new producing schema P3.

To maintain backwards compatibility, new consuming schemas must be backwards compatible with data produced by all the existing producing schemas.
When C2 is added, it must be backwards compatible with P1 and P2.
To maintain forwards compatibility, new producing schemas must be forward compatible with all the existing consuming schemas.
When P3 is added, it must be forwards compatible with C1 and C2.
To put this another way, C1 and C2 must be backwards compatible with P3.
To maintain full compatability, we ensure every consuming schema is backwards compatible with ever producing schema, (both sets of arrows in the diagram above), i.e. all consuming schemas can consume the data produced using any producing schema.
We know a system has fully compatible schema changes if every consuming schema is backwards compatible with every producing schema.
Hopefully this makes sense and even intuitive. The next question is what kind of schemas should these new producing and consuming schemas be if we’re to meet our requirements? Should they use an open, closed or partially-open content model?
Producers of data control the schema of the data. They know the exact set of properties, with no ambiguity. This is a great match for a JSON Schema with a closed content model.
Consumers of data don’t control the schema of the data, but do know the set of properties they read from the data. They can ignore any additional properties. This is a great match for a JSON Schema with an open content model.
Producing schemas should use a closed content model. Consuming schemas should use an open content model.
How does this work in practice?
Let’s walk through the evolution of a JSON Schema using this new way of working.
Let’s start with v1 of the producing application. It produces data that conforms to the following closed schema:
{
"type": "object",
"additionalProperties": false,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" }
},
"required": [ "id", "name" ]
}
…and v1 of one of the consuming application requires data that conforms to the same schema, only with an open content model:
{
"type": "object",
"additionalProperties": true,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" }
},
"required": [ "id", "name" ]
}
This consuming schema is backwards compatible with the producing schema, so we know we are maintaining full compatability.
Evolving the producing schema
So far so good, but what happens if we want to deploy v2 of the producing application with an evolved schema?
The new v2 producing schema contains a new optional checked property:
{
"type": "object",
"additionalProperties": false,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" },
"checked": { "type": "boolean" }
},
"required": [ "id", "name" ]
}
Because the consuming v1 schema is open, it is backwards compatible with this new producing schema,
so we know we are maintaining full compatability.
Evolving the consuming schema
Next, we want to deploy v2 of the consuming application to take advantage of the new checked property.
The new v2 consuming schema is:
{
"type": "object",
"additionalProperties": true,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" },
"checked": { "type": "boolean" }
},
"required": [ "id", "name" ]
}
Both v1 and v2 of the consuming schema are backwards compatible with v1 and v2 of the producing application, so we know we are maintaining full compatability.
Now lets say we realise that v2 of the consuming app is not fit for purpose, and we’d like to roll back the deployment to v1. Is it safe to do so? As we’ve maintained full compatability we know we’re good to roll back.
After investigation into the issues with v2, we’re soon ready to deploy v3 of the consuming application,
which will take advantage of an upcoming enhancement to the producing application.
It turns out the issue was the recently added checked property wasn’t fit for purpose and a new status enum will be added upstream as its replacement.
The new consuming app contains logic to take advantage of the new status property if its present.
The new v3 consuming schema, with the upcoming status property, is:
{
"type": "object",
"additionalProperties": true,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" },
"status": {
"type": "string",
"enum": ["pending", "passed", "failed"]
}
},
"required": [ "id", "name" ]
}
As the v3 consuming schema is backwards compatible with the v1 and v2 producing schemas, so we know we are maintaining full compatability.
Evolving the producing schema late
After the new v3 consuming application is deployed we want to deploy v3 of the producing application, with the new status property.
Normally, we’d probably release a version that produced data with both the old checked and the new status properties for a while.
But, in this instance we know there is only one downstream consumer, which is already prepped to handle status.
The new v3 producing schema, without checked and with status, is:
{
"type": "object",
"additionalProperties": false,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" },
"status": {
"type": "string",
"enum": ["pending", "passed", "failed"]
}
},
"required": [ "id", "name" ]
}
All known consuming schemas are backwards compatible with this new producing schema, so we know we are still maintaining full compatability.
Although all the examples above were checking for full compatibility, this design supports checking for just backwards, or just forwards, compatibility. Not that we recommend you do, mind. If you did you may have found yourself in a hole, unable to revert the bad consumer app.
Negative examples
The above walk through was all ‘happy path’. Does the proposed pattern of checks capture incompatible changes as well? Yes!
Consider what would have happened if a new junior developer had jumped in and tried to change v2 of the producing application
to fix the issue with the checked property.
Rather than remove the old checked property and add a new enum type, the junior developer might just change checked to an enum:
{
"type": "object",
"additionalProperties": false,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" },
"checked": {
"type": "string",
"enum": ["pending", "passed", "failed"]
}
},
"required": [ "id", "name" ]
}
As the v2 consumer schemas isn’t backwards compatible with this producing schema, we know such a changes isn’t compatible.
Likewise, adding or removing required properties also breaks backwards compatability with existing consumers.
Capturing schemas in a schema registry
What schemas do we need to capture to make these proposed evolvability checks work?
Encourage ownership to decouple teams
Before we get to that, let’s first discuss one additional requirement around ownership.
In larger organisations it is often the case that data produced by one team is consumed by applications written and maintained by different teams, potentially in different departments. The use of fully compatible schema evolution can go a long way to removing the need for costly “onboarding processes” and aligned release dates etc. Data becomes more self-service. This is a good thing!
In such an operational model, the producing team owns the data products it publishes for other teams to consume. This model would break if consuming teams were free to register any consuming schema they liked.
Consider what would have happened in the walk through above if v3 of the consuming app had published a consuming schema
with the new status property as an integer rather than an enum?
Maybe because they left the design meeting thinking that’s what had been agreed.
The v3 consuming schema would then be:
{
"type": "object",
"additionalProperties": true,
"properties": {
"id": { "type": "integer" },
"name": { "type": "string" },
"status": { "type": "integer" }
},
"required": [ "id", "name" ]
}
Now, when the producing team tries to release v3 of their app, it will fail as the v3 consuming schema is not backwards
compatible with the v3 producing schema as they disagree on the type of status.
This consuming schema is now dictating the type of status. The producing team can either switch to using an integer or
rename their property, and are forever restricted on the type of any future status property they want to add.
Allowing any consuming schema to be registered by consuming applications removes control of the data’s schema from the team that owns the data. This is not a good thing!
Evolving producing schemas
Keeping control of the schema with the team that owns the data is achieved by something potentially unintuitive: not registering the consuming schema in the schema registry.
Yes, you read that right :)
Let’s look at how this can work:
It’s pretty easy to write code to create an open consuming schema from a closed producing schema. This means we can capture the producing schemas, and synthesis the consuming schemas as needed, i.e. when performing compatability checks:

We keep control of the schema with the data product owner by registering only closed producing schemas in the Schema Registry.
Checking consuming schema compatibility
The eagle-eyed among you may have already noticed in the walk through that in each consuming schema matched the producing schema, except it used an open, rather than _closed, content model.
The most simple process for checking consuming schema compatability is to convert the open consuming schema to a closed producing schema, and then confirming the closed producing schema is already registered. If it is, then the consuming schema has already been checked for compatability.
This simple one-to-one mapping between producer and consumer schemas is efficient, as it only requires a single look-up in the Schema registry when a service starts up.
Having a consuming schema derived from a producing schema also often follows the development and release process of organisations, as downstream teams will often use the latest schema of the data when developing their consuming application.
However, it is not a strict requirement that the consuming schema exactly matches the properties defined in a registered producing schema. It is also possible for a consuming schema to contain a subset of the properties defined in a registered producing schema. More accurately:
To maintain full compatability a consuming schema must be backwards compatible with at least one open schema synthesised from a registered, closed, producing schema.
Using a smaller ‘view’ schema containing only the minimal subset of properties the consuming app reads will decrease the time the consuming app spends validating and deserializing incoming data. But this comes at the cost of service start up time, as the service may need to check multiple schema versions before finding one the view schema is compatible with.
The increased start up costs can be avoided if the consuming application knows the exact producing schema to look up.
What does the implementation look like?
The implementation involves two parts.
Synthesising consumer schemas
The default value for additionalProperties is true, i.e. an open-content model.
This means, given a closed-content model producer schema, it will contain explicit "additionalProperties": false
entries. The closed-content producer schema can be converted to an open-content consumer schema by simple exchanging
those false values for true. e.g.
class SchemaConverter {
public static JsonSchema toConsumerSchema(final JsonSchema producerSchema) {
final String schemaText = producerSchema.canonicalString();
return new JsonSchema(
schemaText.replaceAll(
"\"additionalProperties\":\\s*false",
"\"additionalProperties\": true"));
}
}
Compatability checks
The example code below doesn’t bother trying to implement non-transitive FORWARD, BACKWARD or FULL checks as,
in our opinion, they are not much use given the long-lived nature of Kafka data and distributed nature of modern systems.
Instead, it focuses on checks that test all versions are compatible,
i.e. equivalent to the Schema Registry’s FORWARD_TRANSATIVE, BACKWARD_TRANSITIVE and FULL_TRANSITIVE.
class Example {
/**
* Check its safe to consume with a consumer schema
* derived from the supplied producerSchema.
*
* @param subject the Schema Registry subject
* @param producerSchema the producer schema that the consumer schema is derived from.
* @return id of registered schema.
*/
int ensureConsumerSchema(
String subject,
JsonSchema producerSchema) {
// If the producer schema is registered, we can safely consume with the derived consumer schema.
return srClient.getId(subject, producerSchema.normalize(), false);
}
/**
* Check its safe to consumer with a reduced-view consumer schema.
*
* @param subject the Schema Registry subject
* @param producerSchema the closed-content producer schema that the consumer schema is derived from.
* @return id of registered schema.
*/
int ensureConsumerViewSchema(
String subject,
JsonSchema producerSchema,
JsonSchema consumerViewSchema) {
JsonSchema consumerSchema = toConsumerSchema(producerSchema);
// The reduced-view schema must be backwards compatible with the full consumer schema:
List<String> issues = consumerViewSchema.isBackwardCompatible(consumerSchema);
if (!issues.empty()) {
throw new IncompatibleSchemaException(consumerSchema, consumerViewSchema, issues);
}
// And the associated producer schema must be registered:
return ensureConsumerSchema(subject, producerSchema);
}
/**
* Ensure a producer schema is registered.
*
* <p>If it is not, check compatability and register it.
* @param subject the Schema Registry subject
* @param producerSchema the producer schema to ensure registered.
* @param backwards check backwards compatability?
* @param forwards check forwards compatability?
* @return id of registered schema.
*/
int ensureProducerSchema(
String subject,
JsonSchema producerSchema,
boolean backwards,
boolean forwards) {
JsonSchema normalized = producerSchema.normalize();
try {
// Early out if schema already registered:
return srClient.getId(subject, normalized, false);
} catch (RestClientException e) {
// If not already registered, register:
return registerWriter(subject, normalized, backwards, forwards);
}
}
private int registerWriter(
String subject,
JsonSchema producerSchema,
boolean backwards,
boolean forwards) {
JsonSchema consumerSchema = toConsumerSchema(producerSchema);
// If known subject, i.e. not v1, check compatability:
if (srClient.getAllSubjects().contains(subject)) {
if (backwards) {
checkCompatability(subject, producerSchema, consumerSchema, false);
}
if (forwards) {
checkCompatability(subject, producerSchema, consumerSchema, true);
}
}
// Ensure server-side compatibility checks are disabled:
srClient.updateCompatibility(subject, "NONE");
// Register normalized producer schema in the Schema Registry:
return srClient.register(subject, producerSchema);
}
private void checkCompatability(
String subject,
JsonSchema newProducer,
JsonSchema newConsumer,
boolean forwards) {
// For each registered producer schema:
for (Integer version : srClient.getAllVersions(subject)) {
Schema existing = srClient.getByVersion(subject, version, false);
if (!existing.getSchemaType().equals(JsonSchema.TYPE)) {
throw new IllegalArgumentException("Existing schema is not JSON");
}
JsonSchema oldProducer = (JsonSchema) srClient.parseSchema(existing)
.orElseThrow();
List<String> issues;
if (forwards) {
// Forward: old schemas reading new data.
// all data that conforms to the new (producer) schema
// can be read by the old (consumer) schema:
ParsedSchema oldConsumer = toConsumerSchema(oldProducer);
issues = oldConsumer.isBackwardCompatible(newProducer);
} else {
// Backwards: new schema reading old data.
// all data that conforms to the old (producer) schema
// can be read by the new (consumer) schema:
issues = newConsumer.isBackwardCompatible(oldProducer);
}
if (!issues.isEmpty()) {
throw new IncompatibleSchemaException(newProducer, newConsumer, issues);
}
}
}
}
Presently, these evolution check are implemented client side in the Creek JSON serde under development.
Server-side checks are set to NONE. This does introduce race conditions when registering new schemas.
We’ve raised Issue #2927 in the Schema Registry GitHub repo to hopefully get the improved algorithm into the Schema Registry :crossed_fingers:.
The above code, combined with appropriate calls to ensureProducerSchema and ensureConsumerSchema when creating
serializers and deserializers, respectively, results in appropriate schema compatibility checks to ensure system integrity,
without any need for convoluted patternProperties.
A Voilà, no more PROPERTY_ADDED_TO_OPEN_CONTENT_MODEL or PROPERTY_REMOVED_FROM_CLOSED_CONTENT_MODEL errors from the Schema Registry!