

Comparison of JSON schema validator implementations
One of the big ticket items remaining before Creek can leave alpha is support for serializing complex objects. The first object based serialization format will be JSON, as its easy to view and debug messages with standard tooling, and compresses well. Yes, it’s not as efficient as Proto-buffers or Avro or any number of binary serialization formats. But in our experience, its efficient enough for all but the most high-throughput ‘firehose’ applications, and its ease of use outweighs the performance implications.
The importance of schemas
Perhaps the biggest challenge when deploying any highly distributed architecture is having confidence that deploying a new version of one part isn’t going to break other parts of the system.
In a Kafka based microservice architecture all communication between different services is accomplished by sending data to Kafka. Without suitable guardrails in place, deploying an updated service can easily cause catastrophic failures and issues downstream, e.g. the new version of the service might remove a field required by a downstream service.
Schema compatability
The common solution to this problem is to capture the schemas of the data the service is producing and ensuring any new version of the service has a compatible schema.
Schemas can be backwards compatible, forwards compatible, or both. Briefly, forwards compatibility means data written with one schema version can be read by applications using previous versions of a schema. Conversely, backwards compatibility means data written with one schema version can be read by applications using a new version of the schema.

Backward compatibility means that readers with a newer schema can correctly parse data written using an older schema, i.e. new schemas can read old data.
Forwards compatibility means that readers with an older schema can correctly parse data written using a newer schema. i.e. old schemas can read new data.
Given that data can live in Kafka topics for a long time, e.g. key compacted changelog topics or topics will long, or even no, deletion policies, it is common for Kafka based microservices to encounter both data written with older and newer versions of a schema, regardless of the timing of the release of producer and consumer services. For this reason, it is strongly recommended that you default to ensuring schema changes are both forward and backwards compatible over all versions of the schema.
Any change that breaks compatability needs to be carefully managed to ensure the role-out does not break the platform and, in our experience, is often better achieved by producing data to a new topic in tandem with the old for a period of time. Turning off and deleting the old topic once all consumers have migrated.
See the follow-on post series Evolving JSON Schemas for more info on the specifics of evolving JSON Schemas.
Schema registries
The requirement for schemas to be transitively forwards and backwards compatible, i.e. compatible with all previous and future schemas, necessitates the storing of each version of a schema. This is normally achieved through the use of a Schema Registry of some kind: a service that stores the versions of a schema and often both links those schemas to the resources that use them, such as a Kafka topic, and offers the ability to enforce compatibility between versions.
Schema validation
Having a schema for the data a service is producing, that is known to be compatible, removes the risk of deployments breaking down-stream systems, right? Well… no, not quite. A schema is useless unless there is confidence the data being produced matches the schema. We’ve seen systems with handwritten schemas that differ greatly from the JSON payloads being produced.
It is important that each JSON object being produced to Kafka aligns with the known forward and backwards compatible schema.
In our experience, the best way to achieve this is to build the schema from the code, or the code from the schema, and then to validate each JSON object before producing it to Kafka. Yes, this is relatively expensive. Yes, there is an argument that with perfect testing before deployment this validation step is superfluous. But let’s be honest, how many projects have you worked on with perfect testing?
By validating each and every message before producing to Kafka, you can have confidence your service isn’t going to adversely affect downstream services.
What about validating when reading messages? Surely, as each message is validated before being produced to Kafka there is no need, right? In an ideal world, this would be the case. In the real world, unless your topics are locked down tight so that no person or tool can produce to them without schema validation, then there’s the chance there could be bad data on the topic.
By validating each and every message being consumed from Kafka, bad data is detected before it hits the business logic of a service and can’t contaminate downstream systems.
JSON schema validator libraries
Given the importance of validating JSON data against a JSON Schema, our first step to implementing a JSON serialiser for Creek was to determine which validator implementation to use, and there are many.
When our search for functional and performance comparisons of these different implementations drew a blank, we simply wrote our own to test JVM based implementations, and as we’re nice people we open sourced the code and published the results in a microsite.
The functional comparison is achieved by running each implementation through the standard set of test cases. This covers core required functionality and optional features.
The performance comparison is achieved by benchmarking each implementation using the Java Micro-benchmarking Harness.
The site auto-updates as new versions of the libraries under test are released, and we’re actively encouraging new validator implementations to be added to the test.
The site is linked to from the implementations page on the JSON Schema website.
Note: Project Bowtie is looking to provide functional comparison of all validator implementations, not just JVM based ones. Bowtie was unknown to us when we started writing our own comparison and, at the time of writing, doesn’t cover the optional functional tests.
Comparison conclusions
Feature comparison
The latest functional results can be viewed on the microsite.
The two graphs visualise the overall number of tests each implementation successfully handles in the draft versions it supports.
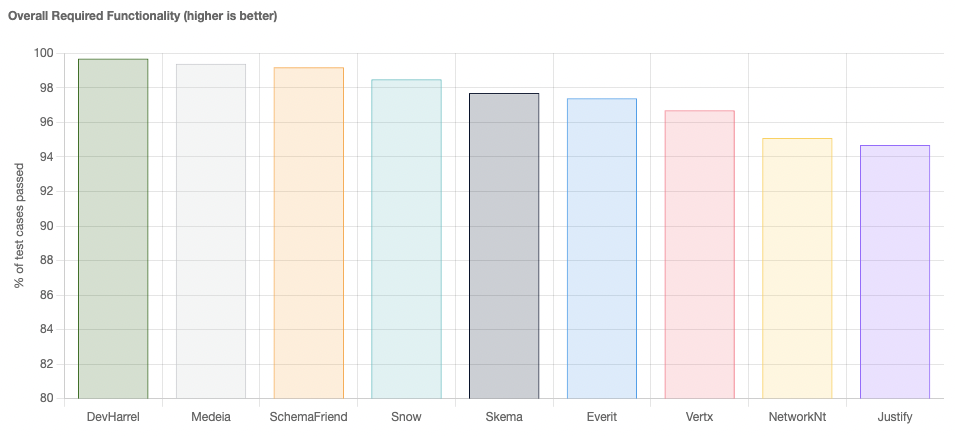
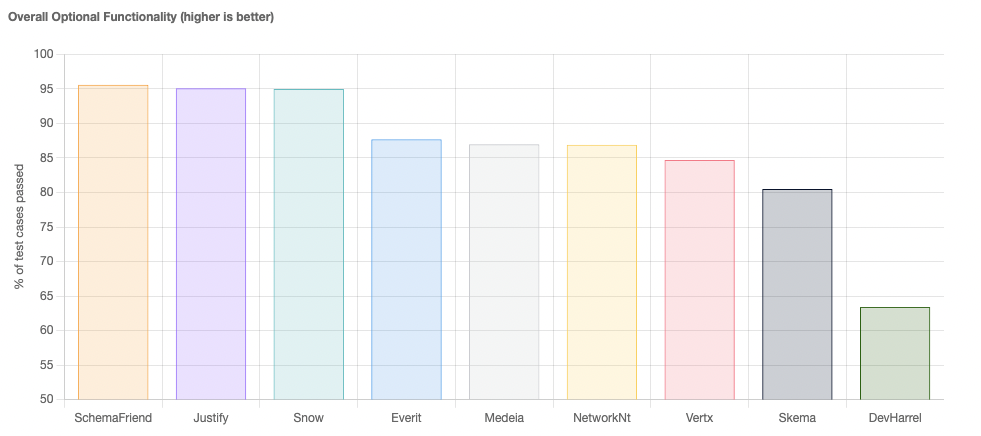
At the time of writing, the top three implementations for required functionality are DevHarrel, Medeia and ScheamFriend.
DevHarrelonly supports the latest two schema drafts,DRAFT_2020-12andDRAFT_2019_09, and doesn’t score so well for optional features.Medeiaonly supports older schema drafts, up toDRAFT_7.SchemaFriendsupports all versions of the JSON Schema and scores well in both required and optional functionality.
To our mind, SchemaFriend wins in the feature comparison.
Performance comparison
The latest performance results can be viewed on the microsite.
The performance comparison benchmarks two different use-cases.
- The first
validatebenchmark runs each implementation the functional test suite. - The second
serdebenchmark runs each implementation through serialising a simple Java object to JSON and back, validating the JSON.
The graphs below capture the essence of the results, covering the latest and an older draft specification. More information is available on the microsite.
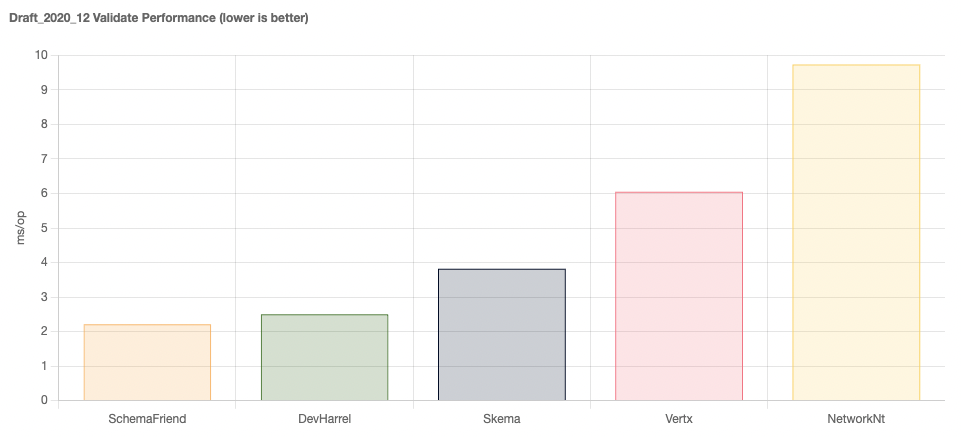
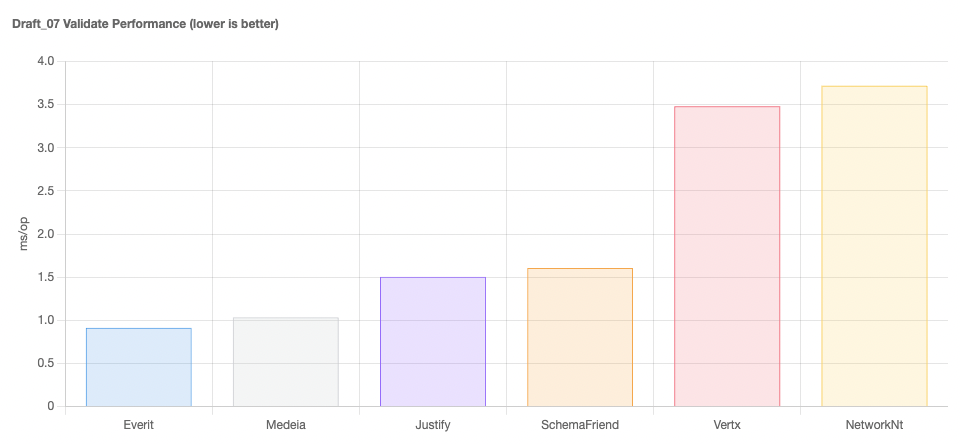
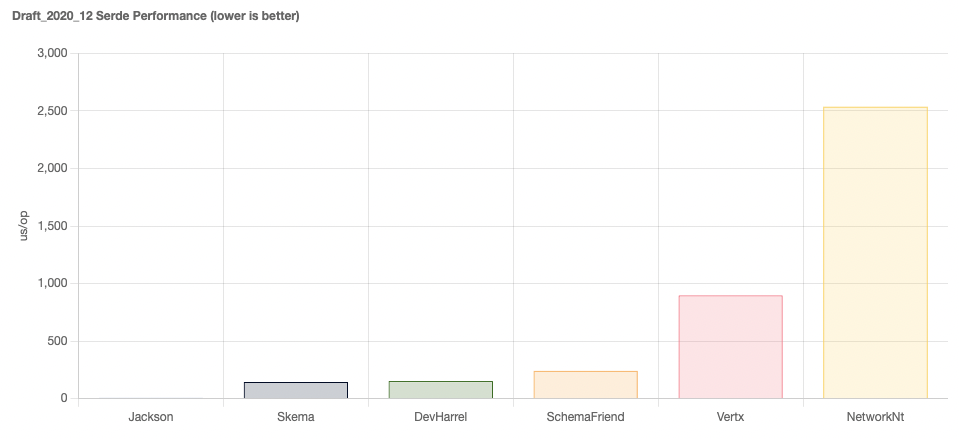
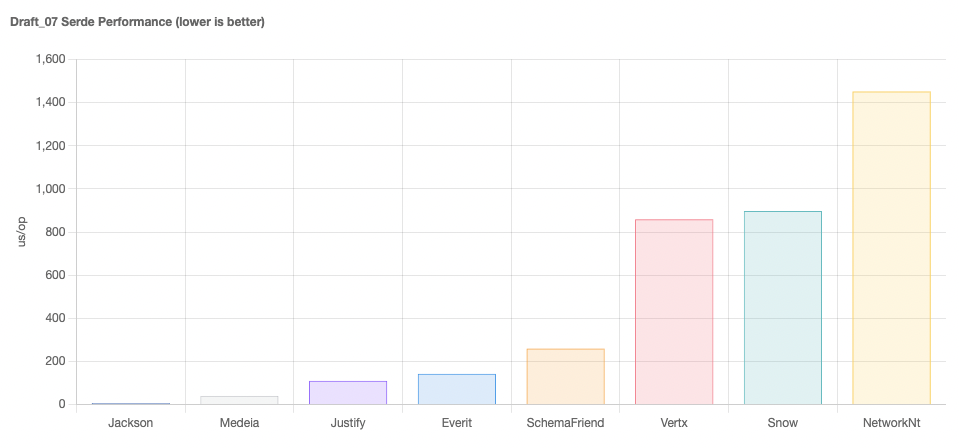
At the time of writing, benchmarking of older schema drafts highlighted Medeia and Everit as clear winners.
For the more up-to-date schema drafts, Skema, DevHarrel and SchemaFriend lead the pack.
Interestingly, the general cost of validation seems to have increased as the JSON schema specification has evolved. This is likely due to more things being possible, but is a slightly worrying trend as it looks to have increased the cost even for the same simple use-case.
To our mind, for pure speed Medeia is hard to beat, and indeed we have used it successfully in previous companies.
Unfortunately, it looks to be an inactive project and only supports up to DRAFT_7.
For newer draft versions, the winners would be Skema and DevHarrel and SchemaFriend
Conclusions
Hopefully this comparison is useful. The intended use-case will likely dictate which implementation(s) are suitable for you.
For its wide-ranging schema draft version support and being near the top in both functional and performance comparisons,
SchemaFriend looks to be a great general-purpose validator library.
If your use-case requires ultimate speed, doesn’t require advanced features or support for the later draft specifications,
and you’re happy with the maintenance risk associated with them, then either Medeia or Everit may be the implementation for you.
It’s worth pointing out that Confluent’s
own JSON serde internally use Everit, which may mean they’ll be helping to support it going forward,
and may mean this is the best choice for you if other parts of your system already use Confluent’s serialisers and hence compatability with Everit’s functionality is key.
Note: The author of this post and the repository is not affiliated with any of the implementations covered.